16th May 2026Python type hints
 In 2002, my colleagues gifted me a Python
book during my farewell party. I started reading it, but when I saw the use of indentation instead of
brackets, my C++ core rejected it.
In 2002, my colleagues gifted me a Python
book during my farewell party. I started reading it, but when I saw the use of indentation instead of
brackets, my C++ core rejected it.
By 2005, however, I was evangelizing Python to everyone. My job description has never included any reference to Python, yet it has been my programming language of choice for the last 20+ years.
I have enjoyed the evolution of the language, and I normally use its latest features—except for type hinting. Although I understand its value, I feel it only pollutes the code. The latest IntelliJ IDEA implementation, where type hints are discovered on the fly and laid out in a grayish font, helps me little and disturbs me a lot. Fortunately, these can be disabled under Editor > Inlay hints > Python. Done.
And, just like the indentation, I guess type definition is a feature I could grow to love. I'm just not there yet.
19th April 2025Truecrypt in MacOS silicon
![]() I have a bunch of hard disks with
Truecryt volumes, and I use a USB 3.0 SATA
docking station to make them available. I have tried recently Veracrypt, but it
couldn't open those drives. I didn't want to install yet an unknown executable
(Veracrypt or Truecrypt) plus MacFuse, etc on my new Mac Mini, so I though on using a Linux virtual
machine: I had just set one up to access the printer, so why not using it to
access these drives?
I have a bunch of hard disks with
Truecryt volumes, and I use a USB 3.0 SATA
docking station to make them available. I have tried recently Veracrypt, but it
couldn't open those drives. I didn't want to install yet an unknown executable
(Veracrypt or Truecrypt) plus MacFuse, etc on my new Mac Mini, so I though on using a Linux virtual
machine: I had just set one up to access the printer, so why not using it to
access these drives?
This is how I implemented this solution.
14th April 2025GCP Professional Architect certification
 I renewed today again my GCP Cloud Architect Professional certification;
I have been certified since 2019, and this was the first time I had the
opportunity to do a renewal exam, as an alternative to the standard
certification exam.
I renewed today again my GCP Cloud Architect Professional certification;
I have been certified since 2019, and this was the first time I had the
opportunity to do a renewal exam, as an alternative to the standard
certification exam.
This means: only 25 questions, only 60 minutes. And half the price :-) And it is a breath of fresh air in comparison to the hyperlong AWS exams, 75 questions where each question requires a long read time. I finished the test in just 35 minutes!
I used a Udemy course, not bad, but severely outdated. The renewal exam has a stronger focused on the Generative AI tools in GCP, which appears nowhere in the course. In any case, is a good overview of GCP, useful to cover the basics.
While there seems to be plenty of AWS courses on Udemy, the GCP offer is very limited; GCP must be huge in India, most if not all instructor are from that country, and none of the courses seemed to be really up to date. At the end, I played a lot with the GCP console, and read additional documentation on the GCP site to consider myself ready for the exam.
There are many synergies between the AWS and GCP exams: at the end, both are evaluating the Architecting knowledge of the user, and the objectives are the same: operational excellence, security, reliability, performance efficiency, cost optimization, sustainability. The tools are obviously different, but the CP exam is less detailed with these than the AWS exam, which requires a more precise knowledge on details on how these tools work. After having already passed the AWS exams, I only needed 10 days to pass the GCP one, with a similar grade of preparation.
It is the AWS exam harder than the GCP one? Definitely: in lenght, complexity and depth; also, AWS requires a higher grade (75) than GCP (70). Is this the best reason to prefer GCP to AWS? Doubtful, you require mostly the same amount of time to prepare for both; but if you are not well prepared, the probabilities to pass the GCP exam are higher. And AWS has a much bigger market share, around three times larger, so my first option is always AWS.
GCP seems to play catch up with many AWS features, but I find really motivating the way other original services are implemented, with big differences in what it could be equivalent services, like IAM, or messaging. At the end I find that I really like the Google platform, but I still prefer the overall approach of AWS, more comprehensive and consistent. I believe I should extend this approach and get into Azure. To be seen...
27th March 2025Apple keyboard
 I bought an Apple magic keyboard with numeric pad,
to pair with my new Mac Mini M4.
I felt stupid to purchase the keyboard with keys in black, costing 30 euros more for the sake of it,
but I have been using the old good keyboard in white for many many years, and I wanted to have some differentiation.
With all my attention focused on the colours, I committed the mistake of requesting the US layout,
when all my previous keyboards had the English International layout. I was totally unaware of the small but
essential differences between both layouts.
I bought an Apple magic keyboard with numeric pad,
to pair with my new Mac Mini M4.
I felt stupid to purchase the keyboard with keys in black, costing 30 euros more for the sake of it,
but I have been using the old good keyboard in white for many many years, and I wanted to have some differentiation.
With all my attention focused on the colours, I committed the mistake of requesting the US layout,
when all my previous keyboards had the English International layout. I was totally unaware of the small but
essential differences between both layouts.
Then you have the differences with the usual extended Apple keyboard, which I have used since always: the left bottom corner has control, option, command keys, while the new Touch Id keyboard adds a Function button on the very left corner, which is prime real state! I have a Macbook Pro M3, and the function key is on the same position. Yet I do not press it usually, but with the extended keyboard having almost the same layout as the old one except for this key, I kept pressing it whenever I need the control key. It was driving me mad (mostly, because I still use the older keyboard with other computers).
This is my story on how to remap the keys in a way that my muscle memory doesn't abuse me. Much.
26th March 2025Unsupported printers in MacOS
 I have an old printer, a nice Samsung ML-1630;
I use it infrequently, but it's essential when I do. I do not keep a exact recollection of the moment I bought it,
but that would have been in 2008 or 2009. In 2019 I changed the toner, and in 2020, during the pandemic,
my wife used it a lot, so I bought another toner which still remains unopened.
I have an old printer, a nice Samsung ML-1630;
I use it infrequently, but it's essential when I do. I do not keep a exact recollection of the moment I bought it,
but that would have been in 2008 or 2009. In 2019 I changed the toner, and in 2020, during the pandemic,
my wife used it a lot, so I bought another toner which still remains unopened.
It is a USB printer that is connected when needed to my desktop computer, running Ubuntu 24.04; I wanted to connect it to my new/alternative desktop, a Mac Mini M4, but alas, it lacks driver support. Trying to use older drivers, or drivers for other Samsung printers, didn't work out.
My solution is to have a virtual machine running debian, sharing the printer, which becomes available as a network printer. I tried first to use UTM, but the associated virtual machine could not see the printer. It seems like VMWare Fusion does not support headless virtual machines easily, so I finally used virtualbox. The steps required are listed here
Mind you, this is not a magical solution: it is equivalent to have a 4 Gb driver, consuming 512 Mb memory and 1 cpu full time: What I do is stopping the VM, saving the state. Then, you can print as many pages as required, they will go to the pool (in MacOS). Whenever the VM is restarted, the pool will be printed.
10th March 2025Specialty AWS Certification
 After
the two professional AWS certifications, I wondered about getting a specialty one. Currently, that means
Machine learning, Networking and Security. I have no ML expertise in AWS, networking would likely require
some hands-on experience that is currently off-limits, so security was the only viable option.
After
the two professional AWS certifications, I wondered about getting a specialty one. Currently, that means
Machine learning, Networking and Security. I have no ML expertise in AWS, networking would likely require
some hands-on experience that is currently off-limits, so security was the only viable option.
I expected it to be a level superior to Professional: you complete the expertise required to a professional degree, and then you go deeper into some specific category. Difficulty-wise, it is however a lighter exam: less scope to cover, fewer questions, and with less complexity than in the DevOps professional. I got also my best mark! (913), compared to the two professional tests. I completed the 65 questions in around 140 minutes, letting me 30 minutes to review questions (which I never do). For comparison, In the DevOps, I spent 27% more time per question, and there were many more questions with multi-choice or multiple answers.
I did my preparation with another Udemy course from Stephane Maarek. I had expected to go very quickly through the material, but it is a long course, and while it is focused on security, it reuses much of the other courses from this teacher. At the end, it implies revisiting a lot of things that are not required for this certification. You can move fast in many parts, but in others the security topic is just an additional step in a whole setup, so some re-reading is still needed. Worse, there are many areas that are security-specific but are treated very lightly. I cannot say that I would recommend this course, although it was my main driver.
In the AWS training and certification site, there are courses, available for free, addressing the required topics, including preparation for the exams. But, as with the other certifications, I just followed the methods that had worked for me in the past: Udemy courses as main scope navigator, and the AWS documentation and AWS re:Post to follow-up on the areas less covered.
In total, I prepared for the exam in ten days, two months considering the time dedicated for the two professional certifications.
28th February 2025Additional AWS Certification
 After the professional architect,
I had to renew the Devops professional, so I followed the same strategy, bypassing the associate exams.
After the professional architect,
I had to renew the Devops professional, so I followed the same strategy, bypassing the associate exams.
The preparation for this exam was a udemy course, plus all the earlier studying for the Professional Architect position. So around three weeks just for this exam, plus the three weeks I had needed for the first certification.
As part of the study, I did several practice exams, also from Udemy. And this was the first time I passed all these practice exams; I thought I was really well-prepared. Then I went to the exam, and the mask fell off. I had extra 30 minutes (accommodation for foreign language) for the exam, and I fully used them. Please note that this was my 13th certification exam with AWS, the third time passing the Devops professional exam, and this was the first time I needed extra time.
The exam was hard. I mean harder, as these AWS exams are already on the tough side. At the end of the exam, I had 20 questions flagged for review; not that I considered the other 55 questions fine: by question 50 I had stopped flagging them, as I was running out of time. Also, there were two or three questions that caught me unprepared (like one covering Route 53 ARC), and I didn't even require flagging them.
I got an 844 mark, so my lack of confidence was unfounded... or my luck astounding :-) Whatever is the grade, I think I have a strong understanding of AWS services, and the technical expertise to develop sound architectures and manage and operate them. Do I think that the two professional exams covered this expertise? Not really, what they do is to flag the lack of the required knowledge, but that is the usual problem with exams and their grading.
It seems that AWS does not give anymore the results after the exams, which I had really appreciated in the past. Now, you need to wait at least a few hours (around five today), go to the AWS certification side and see if you passed it. For what I saw with the certification before, there is still an email arriving to congratulate you, but with several days delay: some broken pipe on the CICD grading architecture :-)
7th February 2025AWS Certification
 I passed last week my Architect Professional certification for AWS,
it is the second time that I have renewed it.
I passed last week my Architect Professional certification for AWS,
it is the second time that I have renewed it.
In previous times, I would study first for the associate certifications -Architect, Dev, SysOps-, and then the professional ones -Architect, DevOps-, even when passing the professional certifications automatically renew the associate ones.
For lack of time, I decided this year to go directly for the Professional certificate. I wrote three years ago: "The associate certifications have a different scope than the professional ones, it is not just about difficulty. They require a more hands-on approach, a more detailed view of specific concepts, including performance, metrics, etc". I still concur with this viewpoint: I missed now working the ropes, but I still remembered quite well a lot of details.
My preparation was based on two courses in Udemy: Ultimate AWS Certified Solutions Architect Professional 2025, from Stephane Maarek and AWS Certified Solutions Architect Professional SAP-C02, from Neal Davis. In my opinion, the first course is much better, even when the second course is more hands-on and has massively better slides. In any case, both courses are still insufficient, you need to go over the official AWS documentation continuously.
I quite liked the exam. Still 75 questions, most of them really long. I hadn't covered all the bases, I was on firm grounds on probably two-thirds of the topics. I estimate that I had twelve answers wrong, so I was able to deduce at least half of the questions that I hadn't studied, or studied in depth. Likely more, as there could be some mistakes on the well-covered questions.
So you can expect to pass some questions just by thinking hard on how AWS develops its solutions. On the negative side, you will miss likely those where the answer includes some imaginary product, and you will need much longer to answer these questions.
08th January 2025Movies catalog
 I made public today another of my
repositories, a Django application
to handle my own collection of movies
I made public today another of my
repositories, a Django application
to handle my own collection of movies
DJMovies is a django application that I started writing on April 1st 2013, to handle my private catalog of movies. In addition to catalog the movies, it exposes through its web interface multiple tools to handle them: homogenize video and audio formats, subtitles handling, etc.
I am quite astonished of the short time I have needed to migrate this application to the latest python version (3.13.1 as of today) and Django version (5.1.4), as I was using before Django 3.0.5. However, I have not tested the application in full, so additional changes will likely be required in the close future. Very specifically, the access to external services is likely not working now.
06th January 2025Old code
 As part of my migration to host my repositories
in Github, I came across an old Java program I had developed in 2007.
As part of my migration to host my repositories
in Github, I came across an old Java program I had developed in 2007.
The program I developed was quite helpful for the task I was doing at the moment. It allowed me to launch a set of tasks on multiple tabs in a single window, set up several virtual network connections, etc.
I chose to write the program in Java, the only easy option to have it developed quickly and with a proper associated GUI. Back then, I was an experienced C++ developer, and little did I know that the position I had left a few months ago would be the last time I had to do any professional C++ programming. Since then, everything has been mostly Java, C, and Python, with some Smalltalk to salt it.
I made this program publicly available around 2010 and have never received any feedback from it. I really doubt that anybody would have found it useful, even if I had added the documentation that it lacked, and, still, I have spent the past weekend just dusting it off, maveninizing it, and correcting many issues that I found.
I have rewritten a lot of it, marveled at the stupidity of my old me at some decisions, and was surprised to find some programming techniques that I consider sound. This is a rewrite of a code that I know I will not use, yet it has brought some fun to my weekend. I guess I can still marvel at the stupidity of my current me :-)
31st December 2024Blog hosting
 After my previous entry on blog hosting, I started looking for alternatives. My blog is static
-I have my own dynamic generator-, so Github Pages is definitely an option.
Mostly when the other usage I have for my VPS is hosting git repositories, probably a match for Github :-)
After my previous entry on blog hosting, I started looking for alternatives. My blog is static
-I have my own dynamic generator-, so Github Pages is definitely an option.
Mostly when the other usage I have for my VPS is hosting git repositories, probably a match for Github :-)
The step is easy enough, just create a Github repository with my github' user name and suffix .github.io, so, in my case: coderazzi.github.io. The site will be automatically visible as https://coderazzi.github.io
The produced website is not just a link to the HTML pages in the repository. Under the hood, Github sets up a job to build a website based on Jekyll, then uploads the produced artifact. To disable this, add a .nojekyll page to the repository root.
It is possible to see what GitHub is doing with the page at the actions page. When changes are pushed to the repository, a new entry will appear here, with queue status. For my pages, it requires around 28 seconds for the deployment process
Now, I would like to use my own custom domain. Again, this is easy enough: go to user's settings, choose Pages and validate the associated domain; in my case, coderazzi.com. This requires adding a TXT record on your domain, as specified in the validation pages.
Then got to the repository for the webpage, go to settings / Pages and set the custom domain. This will obviously fail in a short time, but it creates a commit in the repository, a new file CNAME that just contains the given custom domain.
The DNS provider must be updated to point to Github's servers. In the DNS provider, using the following Github's information ( Github Pages), we add these recordss:
- 185.199.108.153
- 185.199.109.153
- 185.199.110.153
- 185.199.111.153
30th December 2024VPS providers
 I have been using Hetzner
since 2018, where I got a basic server, with 1 vCpu, 20 Gb and 2 Gb RAM.
At that time, I paid 2.91 EUR per month, about 35 EUR per year.
Service has always been top-notch, and I have seen how they have expanded,
offering a great API and an increasing set of services.
I am awed by Hetzner; recently, I started using storage services to mount additional disk space: very smooth, no hiccups at all.
I have been using Hetzner
since 2018, where I got a basic server, with 1 vCpu, 20 Gb and 2 Gb RAM.
At that time, I paid 2.91 EUR per month, about 35 EUR per year.
Service has always been top-notch, and I have seen how they have expanded,
offering a great API and an increasing set of services.
I am awed by Hetzner; recently, I started using storage services to mount additional disk space: very smooth, no hiccups at all.
On the negative side, the price has steadily increased, and I am now paying 4.43 EUR for the same machine I purchased initially. In truth, Hetzner now offers a more powerful machine for the same price -2vCpu, 4Gb RAM and 40 Gb disk space-, but that's it: there is no cheaper offering for a less powerful machine.
I use a VPS mostly to store my git repositories and serve this blog. The Hetzner minimal offering is way overpowered, and I have to pay the associated cost. I can play along, or find a better choice.
Just before Hetzner, I was using OVH. I checked today its page, the cloud offering exhibits a great AWS-style offering, and matching prices! They have as well basic VPS, billed by the month, and the minimum price for a VPS is 4.60 UER / month, reduced to 0.81 EUR/month for the first year. This offer, limited in time, is fantastic value.
Before OVH, I used to check lowendbox, where I purchased many VPSs over the years. I never had any problem with them. Sometimes I would get picky and wanted to get a KVM machine, but otherwise, I always got great service, sometimes paying as little as 1$/month.
The best offer I found today is 10 pounds/year, with Veloxmedia. For that price, I just get 1 Gb RAM and 10 Gb disk. The Web access is primitive at best. You get a KVM machine already spinning a Debian 12 OS. The underlying CPU is a CPU E5-2660, well over 10 years old. Compared to Hetzner, it has a slower network, slower hard disk, faster CPU, and no linux distribution choice. But, on the paper, it is all that I need.
In practice, the reality is slightly uglier. In six days, it has gone offline twice. Once for 16 minutes, once for 28 minutes, with VPS reboot. This is 99.5% uptime, so it is still a great SLA. Still, worse than the 100% uptime I experienced with Hetzner over many years.
I will be checking this VPS this year, but I am now decided to find another solution for my VPS' needs
14th December 2024SSO on AWS plugin
![]() A user of my AWS CodeArtifact Idea plugin
requested the authentication token through a SSO account, so he was forced to
periodically access the command line and do the AWS SSO login process. He asked to
include the login in the plugin, and that is the core functionality added in version 4.1.0
A user of my AWS CodeArtifact Idea plugin
requested the authentication token through a SSO account, so he was forced to
periodically access the command line and do the AWS SSO login process. He asked to
include the login in the plugin, and that is the core functionality added in version 4.1.0
During the SSO login process, AWS displays a URL to initiate the SSO login, and emits a
security code; the plugin just displays this security code:

From that moment, the browser's UI handles the whole process, with as many attempts from the user as required. This can end with success, or with a timeout, although the user can cancel the plugin' progress at any moment
For the time being, this update is only available in the beta channel.
12th December 2024Attack attempts
 I have a VM hosted in Hetzner, running debian.
I enabled fail2ban long time ago, to get IPs banned on failed remote logins.
I had also enabled two-factor authentication at some point, but more recently,
I had decided to disable password authentication and require only SSH keys.
I have a VM hosted in Hetzner, running debian.
I enabled fail2ban long time ago, to get IPs banned on failed remote logins.
I had also enabled two-factor authentication at some point, but more recently,
I had decided to disable password authentication and require only SSH keys.
After getting a new laptop, I generated new ssh keys, but, of course, I could not login in the remote server, as I would first need to add my SSH key. The best way to do it seemed to be using the Hetzner console, but that was in fact a difficult task, as the console automatically displayed a German keyboard.
Rushing to have the task done, I ended up removing by mistake the authorized_keys file. Not a big issue, but the fastest course of action at that point was to enable password authentication: I disabled fail2ban, enabled password authentication, removed the two-factor authentication, and added the required keys.
But with some social interactions in between, the full security was only placed again almost 12 hours later. Big error on my side, so my rush ended up requiring more work, removing the VM and restoring it with a recent backup.
Before removing the VM, I checked the auth.log: I saw 6338 failed attempts to login to the machine, in 11.5 hours. The main offenders were:
- root : 4058 times
- debian : 189 times
- postgres : 38 times
But the whole list included other 249 users: *****,123,1234,12345,123456,abc,abc1,adm,admin,Admin,admin01, admin1,admin2,admin4,administrador,administrator,adminsys,adminuser,agouser,alex,ali,alina,amir, amit,anonymous,ansible,aoki,app,arma3server,avalanche,backup,bin,bitnami,bitrix,bnb,bot,centos,chris,cisco, cloudroot,config,cs2server,csgo,csgoserver,csserver,cssserver,cumulus,customer,danial,dante, DAppNode,data,david,db2fenc1,db2inst,db2inst1,dbadmin,dbus,default,dell,demo,demo2,denis,deploy, deployer,dev,develop,developer,development,device,devops,dhis,discordbot,dixell,docker, dockerroot,dspace,elasticsearch,elrond,endo,enomoto,eos,es,esadmin,ess,ethereum,filecoin, frappe,ftp,ftpadmin,ftp-test,ftp-user,ftp_user,ftpuser,ftpuser1,ftpuser2,gitlab,gpadmin,guest, Guest,guest1,guest2,gyoumu,hadoop,haraguchi,helpdesk,hmr,ikeda,imd,ingres,installer,james, jeffrey,jenkins,jim,kali,lab,laravel,latha,lighthouse,linaro,lotus,manager,marc,market,media, mike,MikroTikSystem,milad,min,minecraft,miningpool,msfadmin,musicbot,mykim,myra,mysql,naveen, netadm,newuser,nexus,noc,node,nodemanager,nuucp,odoo,odoouser,odroid,oozie,openhabian,openvpn, oper,operator,oracle,osmc,pi,proftpd,prueba,ps,qwerty,ravencoin,reza,root1,root123,rooter,RPM, rust,samba,sammy,sanjay,scanner,scylla,sdadmin,serena,server,service,setup,sftpadmin,sftp_user, sftpuser,sinus,sinusbot,sol,sshd,staff,steam,steam1,stefan,student,student10,supervisor,support, sysadmin,system,te,teamspeak,teamspeak3,tech,telecomadmin,test,test001,test01,test1,test123, test2,test3,test4,testdb,teste,tester,testftp,testing,tests,testssh,testtest,test-user, testuser,tiger,trade-bot,ts3,ts3bot,ts3server,ts3srv,tym,ubnt,ubuntu,ubuntuserver,user, user002,user01,user03,user1,user14,user2,user21,user3,user5,userftp,USERID,username,username1, uucp, validator,watanabe,web3,webadmin,x,xdc,zabbix
6th December 2024Idea plugin update
![]() A user of my AWS CodeArtifact Idea plugin asked me
to support multiple maven repository updates at once when generating a new AWS credentials token.
A user of my AWS CodeArtifact Idea plugin asked me
to support multiple maven repository updates at once when generating a new AWS credentials token.
One option was to provide the repository ids with checkboxes to select those to be updated. But there was the possibility that those repositories were associated to different accounts, so I decided to include the concept of configurations:
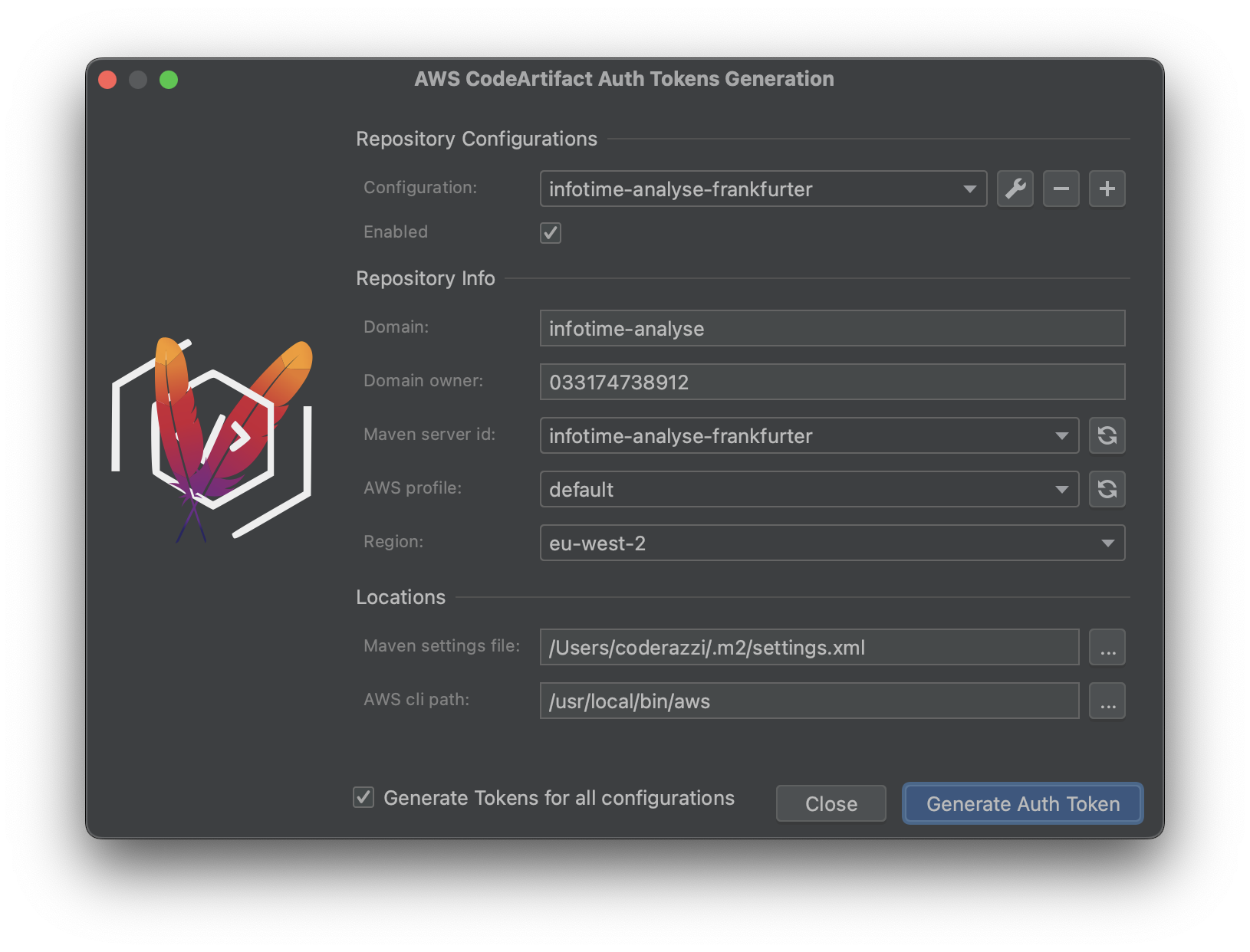
Most users will only need one single configuration, so the added functionality makes the plugin more cumbersome to use, but I could not design a simpler interface that would still support the new feature.
1st December 2024Ubuntu 24.04
 My current unstated policy is to use
MacOS on my laptops, Ubuntu on my desktops, and Debian on my remote servers.
I never rush to install the latest available version, so when Ubuntu 24.04 LTS became available,
I waited six months before installing it, using the fixed 24.04.1 version.
My current unstated policy is to use
MacOS on my laptops, Ubuntu on my desktops, and Debian on my remote servers.
I never rush to install the latest available version, so when Ubuntu 24.04 LTS became available,
I waited six months before installing it, using the fixed 24.04.1 version.
Another part of my unstated policy is not to upgrade the operating system, opting instead for a complete re-installation. This really cleanses the machine, removing a lot of garbage. The main exception to this policy is the remote servers, where I prefer the upgrade path.
Alas, I opted to upgrade to Ubuntu 24.04.1 this time, and it went smoothly. But waking up the machine from its suspended state failed quite uniformly, so after a few days of delaying the inevitable, I reinstalled it from scratch. I tried configuring the system using my last documented setup,, but enough things had changed since then: time for a new version
11th August 2024M3
 In June, two months before its seventh
anniversary, my Macbook Pro added a screen failure to its long list of aches: I could not open anymore
the screen more than 40 degrees. I needed an urgent replacement.
In June, two months before its seventh
anniversary, my Macbook Pro added a screen failure to its long list of aches: I could not open anymore
the screen more than 40 degrees. I needed an urgent replacement.
But my urgency and my requirement to have an English keyboard didn't go together well: local retailers offered me an instant purchase for the local keyboard, not English, and the Apple website offered the proper keyboard with a two-week delivery time, mostly the same as purchasing it from Amazon.co.uk
So I ordered a MacBook Air 15". with 16 Gb of memory, and learned to use my faulty Macbook Pro, connecting it to my monitor / keyboard at home, and using a rather comical position while traveling. Fortunately, the delivery of the new laptop happened in just five days
I had ordered the laptop in the traditional silver color, and it was quite indistinguishable from the MacBook Pro 15", in size. And it was much lighter, and faster, but the screen was duller, it made me unease, so I returned it and purchased instead the Macbook Pro 14", forcing myself to another week of enduring the faulty screen in the old laptop.
I had been using my old Macbook Pro 13" from 2011 for many years, traveling everywhere, and enjoying its compactness. Then I upgraded in 2017 to the Macbook Pro 15", and it was now inconceivable for me to use a smaller screen. But the Macbook Pro 16" is too heavy, and I disliked the screen of the Macbook Air, so I had only one option left. And now I reckon that it is the perfect size for all my needs, and more especially, for carrying it around, which is the main idea of a laptop, right?
I still have the old Macbook Pro 13" from 2011. Its battery lasts half an hour, and I could easily replace it, for less than 50 euros. It is a very dependable computer, completely left out from security updates, so it is also a hazard now (but I only use it in a very strict environment). The Pro 2017 is a much finer machine, with a faulty keyboard, a faulty T1 chip, and a broken screen connection. The Pro 2024 looks sturdier, let's see how long it lasts.
23rd January 2024Touchbar
I thought I would have already replaced my Macbook Pro 15" from 2017 as my main computer.
Its battery has gone from bad to problematic.
Servicing it is recommended, although it can hold the charge quite well, even for a few hours.
However, recently, even when fully loaded, it can report suddenly no charge
-normally when subject to low temperatures-, so the laptop refuses to start.
It is enough to connect it to the powerline to quickly show back 100% charge,
so I need now to carry continuously a powerbank.
The new Pro 16" seems a beast, but it is quite heavier and chunkier. I will miss its thin keyboard and the touchbar, that so many people despise. The touchbar is normally working fine, but sometimes it refuses to light on, or the ESC key appears but the bar does not recognize if I press it. At least I found now a quick solution: killing the "TouchBarServer" application and restarting it.
I reckon that I will update the laptop before the Summer, when it will turn out seven years old. But I wonder what will be the replacement: the Air 15", possibly with M3, should cover me well, but I work often enough outside as to prefer the Pro 16" screen, if its extra 700 grams do not weight me down...
27th March 2023Adding region support
![]() After some time, I
finally added region support to my codeartifact maven Intellij Idea
plugin
After some time, I
finally added region support to my codeartifact maven Intellij Idea
plugin
Just uploaded to the beta channel, it should be available to everybody in a few days.
17th Match 2023Apple service
In the last 17 years, I bought 7 Apple products for
myself: an Apple Mini (2006), an iPod shuffle first generation (2007), a MacBook Pro 13" (2011), and a
Macbook Pro 15" (2017), and three Apple Keyboards (Aluminium, 109 keys, all bought between 2008 and 2012).
Update: I had purchased in fact eight Apple products, the additional one an Apple trackpad in 2011, which
in fact I use regularly
The Apple Mini had several upgrades (memory, CPU, operating system, to Linux), and is now retired, but ready to boot. The iPod shuffle is hidden from me in some box (also hiding from me), and I doubt of its working condition. I use actively two of the Apple keyboards, the third one was lost in my office during the pandemic. The MacBook Pro 13", which was also upgraded (memory, SDD), is now a relic, receiving no updates from Apple and capable to stand no more than 30 minutes without a power plug.
I tried to update its battery in Apple around 2016 or 2017, but Apple had already moved it to legacy category and refused the much needed battery transplant. My wife uses it as her main computer, much to the peril of her banking transactions.
The Macbook Pro 2017 15" is my battle horse on the move, and man, do I move. It is almost 6 years old and the battery gadget displays now a Recommended service label. It retains 4916 maH from the original 7336 maH capacity, or 67%. A general recommendation is to change the battery when it has lost 20% of its capacity; more importantly, it can survive some of my flights, but with careful orchestrated charging, so it is definitely a good time to change it. And it is not yet a legacy Apple product, so I could get it officially serviced, yabadababadoo!!
But not, I cannot. Or better said, I can, if I first transplant also the motherboard and whatnot.
You see, this laptop has the beautiful, but troublesome, butterfly keyboard. Two years ago I tried to have the keyboard serviced using the Apple warranty, but it was denied: some motherboard sensor had detected some liquid spilling. So Apple said that the computer needed to be repaired (motherboard change), before they could change my keyboard for free. We were all gentlemen, so no price was mentioned. It was understood that I would not be changing my perfectly working laptop at Apple service prices because a sensor said so.
Honestly, the keyboard didn't trouble me. I had to install the Unshaky application, which solved the problems I had with my 'b' key, but I thought that in case of selling it, it would have a better price with a renovated keyboard. I thought it was a bollocks policy to dismiss a service because another part could be damaged (and yes, the motherboard is a massive part, but again, I am speaking about a perfectly working laptop).
The problem is, now I cannot either change my battery. Sure, I can go off channels and have it serviced, but what service is Apple giving me here?
I used to have Hackintosh desktops, but since 2017 all my home computes run Linux. I had a XPS 13 laptop running Linux until precisely 2017, and the updates could prove too problematic. Six years later, the situation is perhaps different, but I know that my Apple laptops have never given me any problems. I wish Apple Service was the same...
17th Dec 2022Always humble
 I had some time off and decided to do a bit
from .
I am one year behind -and more-, so I was on day 14 of year 2021.
I had some time off and decided to do a bit
from .
I am one year behind -and more-, so I was on day 14 of year 2021.
The first part, as usual, was easy, and the second part could not be solved using the basic approach, as the final string would require some terabytes of memory, plus all the CPU resources to generate it.
Basically, we would start with a short string, 4 to 20 characters, and its length would be doubled on each iteration, for a total of 40 iterations.
I had the idea of a division and conquer method, as the string could be split and each part handled separately. This solved indeed the problem: I first obtained all the basic strings of a 8k characters that were generated after 13 iterations, and all the next iterations would produce some of those basic blocks. Then, I had just 27 iterations to handle, still long computation time, but manageable. My solution was a bit complex, the code not very long, and it required just over four minutes:
import re
def get_input(test_mod=""):
with open('input/%s%s.input' % (__file__[-5:-3], test_mod)) as f:
return [x.strip() for x in f.readlines()]
def read_input(lines):
pattern = re.compile('^([A-Z]{2}) -> ([A-Z])$')
rules = {}
for each in lines[2:]:
match = pattern.match(each)
rules[match.group(1)] = match.group(2)
return lines[0], rules
def basic(template, rules, times):
for _ in range(times):
applied = [[a + rules[a+b], b] for a, b in zip(template, template[1:])]
template = ''.join([x[0] for x in applied] + [applied[-1][1]])
return {c: template.count(c) for c in sorted(set(template))}
def dividing(template, rules, times):
def apply_rules(base):
applied = [[a + rules[a+b], b] for a, b in zip(base, base[1:])]
return ''.join([x[0] for x in applied] + [applied[-1][1]])
def find_all_units(base):
mem_length, memory, stack = len(template), {}, set([base])
while stack:
use = stack.pop()
if use not in memory:
applied = apply_rules(use)
pre, suf = applied[:mem_length], applied[mem_length-1:]
memory[use] = (pre, suf, {c: use.count(c) for c in set(use)})
stack.add(pre)
stack.add(suf)
# convert the strings to integers, easing up comparisons....
intern = {s: j for j, s in enumerate(memory.keys())}
memory = {intern[k]: (intern[v[0]], intern[v[1]], v[1][0], v[2])
for k, v in memory.items()}
return memory, intern[base]
def apply_with_cache(base, t, memory):
frequencies, stack = {c: 0 for c in rules.values()}, [base]
use = 1
while t > 0:
current, stack = stack[:use], stack[use:]
t, use = t - 1, use * 2
for each in current:
assoc = memory[each]
stack.append(assoc[0])
stack.append(assoc[1])
frequencies[assoc[2]] -= 1
for each in stack:
for c, f in memory[each][3].items():
frequencies[c] += f
return frequencies
# let's apply rules a number of times. We apply first 13 times the rules,
# that will produce a template of length 2^13 multiples by the original
# length (8192 x original length)
for iteration in range(13):
template = apply_rules(template)
if iteration == times-1:
break
# now, template has odd length. To calculate its next step, we can
# divide in two parts of the same length as the current template. And to
# calculate the next step, we divide again, now in four parts of the
# current template. The advantage is that eventually, all divisions are
# just evolution of the same strings. Let's first calculate all the base
# strings (all with length 8192 x original length)
cache, start = find_all_units(template)
# now, we decompose continuously the template in two parts, until we reach
# the given number.
return apply_with_cache(start, times-iteration-1, cache)
def solve(frequencies):
times = sorted([f for f in frequencies.values() if f])
return times[-1] - times[0]
def main(cases):
for test in cases:
if test:
use, echo = '.test.%d' % test, 'Test %d : ' % test
else:
use = echo = ''
template, rules = read_input(get_input(use))
print('2021 - %s02.1 :' % echo, solve(basic(template, rules, 10)))
print('2021 - %s02.2 :' % echo, solve(dividing(template, rules, 40)))
main([1, 0])
Still, I was not happy with the solution. Then I looked into a hint on this problem, about focusing on the generated pairs themselves, and it was enough to create this other solution, much more elegant, much simpler, and faster.
import re
def get_input(test_mod=""):
with open('input/%s%s.input' % ('14', test_mod)) as f:
return [x.strip() for x in f.readlines()]
def read_input(lines):
pattern = re.compile('^([A-Z]{2}) -> ([A-Z])$')
rules = {}
for each in lines[2:]:
match = pattern.match(each)
rules[match.group(1)] = match.group(2)
return lines[0], rules
def pairs(template, rules, times):
def inc_dict(d, k, v=1):
d[k] = d.get(k, 0) + v
base = {}
for a, b in zip(template, template[1:]):
inc_dict(base, a+b)
for i in range(times):
update = {}
for bk, bv in base.items():
inc_dict(update, bk[0] + rules[bk], bv)
inc_dict(update, rules[bk] + bk[1], bv)
base = update
frequencies = {template[-1]: 1}
for bk, bv in base.items():
inc_dict(frequencies, bk[0], bv)
times = sorted([f for f in frequencies.values() if f])
return times[-1] - times[0]
def main(cases):
for test in cases:
if test:
use, echo = '.test.%d' % test, 'Test %d : ' % test
else:
use = echo = ''
template, rules = read_input(get_input(use))
print('2021 - %s02.1 :' % echo, pairs(template, rules, 10))
print('2021 - %s02.2 :' % echo, pairs(template, rules, 40))
main([1, 0])
I had really spent some time figuring out the original solution: I saw a process (dividing the complexity to solve it), and focused into it, instead of backpedaling and trying to figure out a different focus. Why? I guess that because my initial solution was manageable, although barely (42 or 44 iterations instead of 40 and my solution would have made it useless).
Lesson learnt (again :-) on finding alternate solutions....
16th Nov 2022CodeArtifact and MFA
![]() A request I have received
repeatedly about the CodeArtifact+Maven plugin
is the support for multifactor authentication.
A request I have received
repeatedly about the CodeArtifact+Maven plugin
is the support for multifactor authentication.
The request was to prompt the user to enter the MFA token, but when I tried setting up a user with MFA, I could not manage to get AWS to prompt me for that token. Alas, the problem is that MFA can be setup for role profiles, or for user profiles, and only in the first case AWS prompts for that MFA token
I have documented this issue separately and upgraded the plugin to include this support. For the moment, only role profiles are supported.
29th October 2022Kubegres K8s operator
 I have been using in a test AWS Kubernetes environment, Kubegres, a PostreSql operator, without any issues.
I have been using in a test AWS Kubernetes environment, Kubegres, a PostreSql operator, without any issues.
The version I installed was 1.15, using one replica with backups (to EFS) enabled.
The operator does not seem to be in heavy development -or it is considered mostly stable-. There is a new 1.16 version since September 2022, but I haven't tried yet the upgrade.
Alas, I had my first issue recently, when the replica POD failed to start, which resulted in missing backups.
All due to the usual error of volume node affinity conflict, caused by a more bizarre error behind.
25th September 2022Virtualbox mount points
 Starting a Linux virtual machine in Virtualbox, I got the typical emergency mode error
Starting a Linux virtual machine in Virtualbox, I got the typical emergency mode error
Welcome to emergency mode! After logging in, type “journalctl -xb” to view system logs, “systemctl reboot” to reboot, “systemctl default” or ^D to try again to boot into default mode.
The error was related to a shared folder I had setup, which was not accessible. The entry in /etc/fstab read:
Infrastructure /mnt/infrastructure vboxsf rw,nosuid,nodev,relatime,uid=1000,gid=1000 0 0
And checking the virtualbox machine settings, I was still creating the mount point:
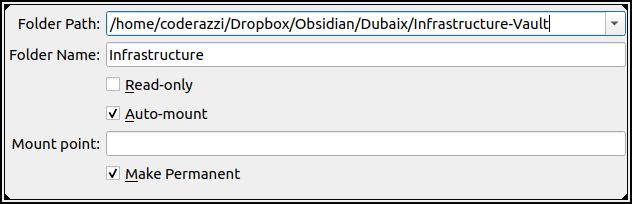
The problem was that the virtual box application had been updated, as well as its extensions, but the guest additions had not been updated in the virtual machine. As a result, the shared point was not reachable, and because there was no nofail attribute in the mount point, the kernel entered into emergency mode.
To solve the issue:
cd /opt/VBoxGuestAdditions-6.1.26/init sudo ./vboxadd setup sudo reboot
Obviously, update the first line to reflect the current guest additions version (6.1.26 in my case)
29th March 2022Pixel 6
![]() My pixel 4A (5G) has lasted me around 11 months.
One crash too many, and the screen became green on one part, rainbow-ish on the other, useless on its whole.
I sent the mobile for reparation to Google. Response: reparation not possible, a refurbished phone is awaiting for 329 EUR.
Considering that the phone costed me 399 EUR, and that I got a company discount for new phones, but none for repairs, I decided to purchase a new mobile.
My pixel 4A (5G) has lasted me around 11 months.
One crash too many, and the screen became green on one part, rainbow-ish on the other, useless on its whole.
I sent the mobile for reparation to Google. Response: reparation not possible, a refurbished phone is awaiting for 329 EUR.
Considering that the phone costed me 399 EUR, and that I got a company discount for new phones, but none for repairs, I decided to purchase a new mobile.
In the meantime, I had to resuscitate my old Pixel 2. Battery issues notwithstanding, the phone is in really great condition. It has fallen many many times, yet not lasting crashes. The pixel 2 is smaller, with a Gorilla Glass 5 front, while the pixel 4a is only Gorilla Glass 3. I found a good online offer, the Samsung S20FE for 379 EUR, but alas, I am not very fond of my own experiences with Samsung phones, and it has just a Gorilla Glass 3 front screen, with upon my own history with the Pixel 4a fall survival rate was discouraging, at best.
So, I added 200 EUR to my budget and got a Pixel 6. Glorious Gorilla Glass Victus, a lot of great reviews, but subject to the underwhelming Google support Service.. I hope this phone will live up to his expectations, I do not see myself getting into the alternative, iPhone territory...
However, this was somehow irrational: pixel 2 is working fine, but just out of support, plus really bad battery life. Pixel 4a destroyed after a few falls -and none really outstanding-. My brother bought a Pixel 4a after my recommendation, and he got a bad one, requiring a replacement. Which is ok, if not because Google support was really bad and he had to resort to consumer protection to get his value back. I guess I am just too invested in Android and I consider Google to be the only acceptable provider, which seems anyway a disputable call...
I have now installed the basics, usual Google applications, and spent quite a long time installing the latest updates. I decided not to copy or transfer data from my previous installation, and start anew. So I went to the Play Store website, My Apps, and started installing the chosen ones... Not an easy choice, My Apps in Google Play shows all the applications I have ever installed in any of my Android smartphones or tablets. It is possible to select a specific category, out of 33 categories, excluding games -which has, on its own, 17 sub categories-. I would have liked to just choose the applications that existed on my previous Pixel 4a, as those were the applications I was using on a daily basis. At then end, I just installed:
- Amazon
- Authy
- Brave
- Feedly
- Firefox
- Google Authenticator
- Google Find Device
- Google Fit
- Google Lens
- Idealo shopping
- Kindle
- Microsoft Authenticator
- Microsoft Teams
- NetGuard
- Opera
- Signal
- Skype
- Slack
- Solid explorer
- Tik Tok
- Uber
- Vivaldi browser
- Yahoo email
- Zoho email
- Zoom
17th March 2022Comparing AWS and GCP Certification
After my previous blog on the AWS certification, I would like to compare it with GCP, both on difficulty and
overall interest and approach.
In my view, AWS exams are very AWS-centric, you can mostly discard any exam answer that includes non AWS technology or cumbersome processes, like writing custom scripts, etc: allegedly, AWS has already developed some automation processes for you.
Google exams are much more open, more focused on software architecture, and choosing a non Google technology on any exam question is often the answer. But Google exams are less demanding, with more time to answer each question-, and overall I find them easier, as long as you have an architecture background.
There are not as many services in GCP as in AWS, but there are also much fewer courses online with good quality. As an additional remark, I find GCP much more consistent in their services implementation. In AWS you can understand the background of the processes and still wonder why some specific processes work the way they do, and the answer is probably that they haven't got the time yet to implement it in a different manner.
Perhaps more importantly: how interesting is it to get the AWS or GCP certification? Very, very much. CV-wise is definitely a nice to have, and a good discriminator. But better than this, it is a good way to expose yourself to a lot of technologies that you probably don't touch on a daily basis.
Said this, I find more interesting, globally, the Google certification than the AWS one, in that it focuses much more on plain Architecture, site reliability, and technologies that you can use inside or outside GCP. The AWS professional architecture certification focuses in many aspects very specific to AWS, like AWS organizations, hybrid scenarios, migrations to AWS, that have no scope on your architecturing work outside AWS.
17th March 2022AWS Certification
 I completed yesterday my AWS re-certification, the three associate and the two professional levels, so I wanted to write some of my observations on the process.
I completed yesterday my AWS re-certification, the three associate and the two professional levels, so I wanted to write some of my observations on the process.
- In 2016 I got the associate Architect certification. I did it reading one book: Host Your Web Site In The Cloud, By Jeff Barr (978-0980576832). This was a book already outdated -from 2010-, so I had quite a lot of hands-on and reading the AWS documentation. Plenty easier than now, of course.
- Although my certification expired in 2018, I had one additional year to meet the recertification deadline, and I effectively passed it in 2019. The certifications expire now in three years instead of two, but somehow I had expected to have that additional year for the recertification deadline, which seems not to be anymore the case. As a result, I have had a few stressful months to comply with the deadlines (bad planning on my side).
- In 2019 I purchased three courses in Udemy, one for each associate exam, from Ryan Kroonenburg (cloudguru). At around 10$ each, they have had tremendous value, as they were mostly my only source to pass the certifications in 2019, and again in 2022. However, they are now a bit outdated: perhaps not much, as they added a few videos, but considering that you need to get a 720 mark in the exam, any missing concept is a problem.
- In 2019, I passed the professional exams by going through the AWS whitepapers, after passing the associate exams. Lots of reading, lots of learning, lots of time spent on the process, which I had at the time. In 2022 I have found a new course in Udemy for the Architect exam, by Stephane Maarek, that is really good. I have used another course from him for the DevOps exam, which is arguably better having more hands-on experience, but I definitely preferred the only-slides approach of the Architect course.
- I have required a bit less than seven weeks to study and pass the five certifications. Considering working and spare time, this amounts to around four to five days for each certification, so it implies quite a lot of dedication. And I know that is quite a short time, but my professional activity involves both architecture and AWS projects management, so I was not starting from scratch.
- The courses above focus too much on the exams, and the kind of questions you can face. As a result, they can enter into detail into some areas just for the benefit of some specific exam question. They lack a focus on explaining the background of the issue, which is what you need, not only to master AWS, but also to pass the examination. If you understand why or how AWS implements Cloudwatch subscription filters, you should be able to answer immediately that a subscription filter cannot export data to S3 directly, but that it needs something like Kinesis Firehose to do so. Why do some actions handle only SNS notifications while others allow lambda integrations? If you focus on AWS this way, you will understand it much better, and have many more options to pass the exam.
- The associate certifications have a different scope than the professional ones, it is not just about difficulty. They require a more hands-on approach, a more detailed view of specific concepts, including performance, metrics, etc. However, passing the professional certification automatically renews the associates ones below: not sure why, as, again, the scope is different.
- Studying for the associate certifications facilitates studying afterwards for the professional ones. But studying the professional ones, much broader in scope, would make it much easier to pass the associate ones. I would suggest trying the associate exams first, and passing them or not, go then for the professional ones.
- The DevOps professional exam was the most difficult exam for me: from the very first question I was walking in quicksands. I was definitely far less prepared, but the questions were also much trickier. It was the only exam that I finished with just a few minutes left, and I was really careful managing my time.
- The exams are not easy. The professional ones require a lot of knowledge. Plus, you have in average 2m 40 seconds to answer each question, and many questions are long enough to require that time just to understand the problem. Normally, for one-answer questions, there are only two answers out of four that make sense, and thinking long enough gives you the answer -if you have the time, that is-. For the Devops, the final two acceptable answers for each question still make plenty of sense, you need to know the specific AWS implementation to get the answer right.
22nd Feb 2022AWS SysOps certification
 I am currently doing the re-certification for my AWS certificates: I hold the three associate
certifications (Solutions Architect, SysOps Administrator, Developer) and the two professional
ones (Solutions Architect, DevOps Engineer).
I am currently doing the re-certification for my AWS certificates: I hold the three associate
certifications (Solutions Architect, SysOps Administrator, Developer) and the two professional
ones (Solutions Architect, DevOps Engineer).
I have renewed this month the three associates, and I am not sure if I will have the time to renew the two professional ones before expiration, in 4 weeks.
The experience so far is that the exams are getting more complicated, definitely no more simple questions like which service would better fit a given functionality, and more ambiguous scenarios. In the case of the SysOps, there were now, in addition to the quizz questions, three exam labs, with the consequence that the result was not available anymore immediately after the exam, unfortunately.
I had 50 questions in my test; I have seen other people mentioning 53 and 55, so I am not sure if there is some randomness in the number of questions, or just the normal evolution of the test. I do usual administration in AWS, but the three tasks requested during the exam were definitely outside my expertise. Moreover, the usual help support is missing, as documented, so you need to perform those tasks quite blindly. Still, the console design in AWS follows good practices and most tasks can be performed quite intuitively; I think I passed them without too many issues, and the final report was fine on my performance during the labs. As a note, copying and pasting during the labs is definitely a headache and something that should be improved for these labs.
After the exam there is just a note that the results will be received in 5 business days. The official documentation mentions that this CAN be the case: I imagine that passing perfectly the 50 quiz questions could already provide a 790 score, enough to pass the test even with the worst results during the lab questions. I received the results, like for all my exams, on the day after the examination, at 21:01 in the evening.
27th Jan 2022Obsidian
 I have been using a basic editor to keep all my notes, and the result is definitely sub-optimal.
I have been using a basic editor to keep all my notes, and the result is definitely sub-optimal.
Evernote had worked quite fine in the past, and I do not recall well why I stopped using it: probably the lack of a linux client, or the web interface letting me down too many times.
I have started now using Obsidian and it looks pretty nice: it stores the notes in markdown, so it is basically plain text. It is less visually appealing than Evernote, but the linking and navigation between notes is clearly an advantage.
This is my current obsidian setup, including my way to have multiple devices sharing files -using Dropbox- plus version control -git-.
27th Jan 2022CodeArtifact and profiles
![]() I have just submitted
a new version of the CodeArtifact+Maven plugin,
with additional functionality to support AWS profiles.
It now parses the AWS configuration files to find any defined profiles, which are then used to request
the authorization token.
I have just submitted
a new version of the CodeArtifact+Maven plugin,
with additional functionality to support AWS profiles.
It now parses the AWS configuration files to find any defined profiles, which are then used to request
the authorization token.
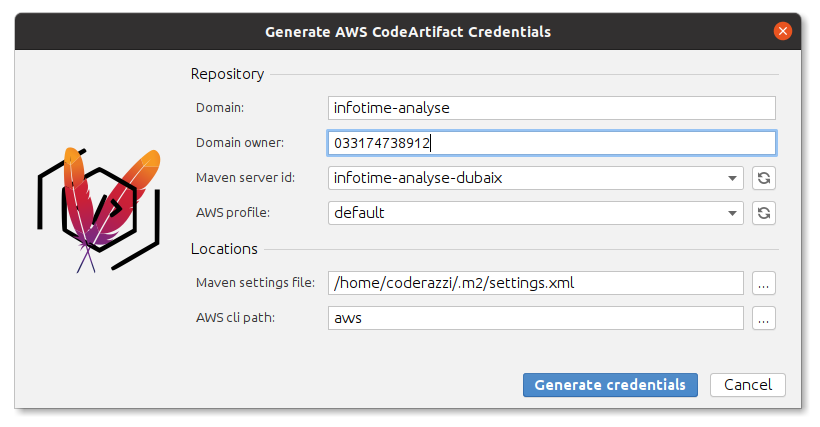
The plugin's window is getting bigger and bigger, with more fields to fill, although the latest added files are handled as comboboxes already pre-filled, so the complexity should not increase:
5th Jan 2022OpenAPI for AWS - python
 The
openapi4aws utility had an initial implementation in python, and
I developed the java / maven version to have a clean integration in our build processes, which uses maven.
The
openapi4aws utility had an initial implementation in python, and
I developed the java / maven version to have a clean integration in our build processes, which uses maven.
After integrating it in our maven poms, we had still the need to update the resulting API gateway specifications on the fly, to reflect changes in the used k8s endpoints. So I decided to modify the original python implementation to reflect the changes introduced in the java version.
The result is a single python file with under 250 lines of code, and two thirds of the code is used just to handle the configuration parameters. I had fun migrating the data structured from Java -implemented as classes- to Python, where I used a mix of classes, dictionaries and data classes.
This version is available as a python wheel
16th Dec 2021Git origins and main/master
 I keep source code repositories in github,
but not for all my projects. I keep also my own git repository on a VPS, backed up regularly,
which hosts my private projects, plus the public ones hosted in github.
I keep source code repositories in github,
but not for all my projects. I keep also my own git repository on a VPS, backed up regularly,
which hosts my private projects, plus the public ones hosted in github.
To keep a repository synchronized both to Github and to my private Git repository, I usually create first my private git repository, then create a repository in Github with the same name. Afterwards, I need to add github as a remote repository; for example, for my project openapi4aws-maven-plugin, I would do:
git remote add github git@github.com:coderazzi/openapi4aws-maven-plugin.git git push -u github main
Now, changes can be pushed to my private repository doing:
git push origin
And to Github doing:
git push github
Github did recently (October 2020) a migration on the default branch, from master to main, which means that, at least for any new repositories, I would better follow the same approach to ensure that I can push changes to github and my own private git server.
In my private repository, I can rename my default created branch from master to main doing:
git branch -m master main git push -u origin main git push origin --delete master
But this last command will likely fail, with a message: deletion of the current branch prohibited. To solve it, go to the git server, and access the folder where the git repository is stored, then do:
git symbolic-ref HEAD refs/heads/main
Now, on the local repository, the command git push origin --delete master will work as expected
12th Dec 2021OpenAPI for AWS
I am working on a project where we define
the interfaces of all microservices using Swagger, and then generate the API gateway specification
dynamically. AWS allows importing an openapi specification to define an API gateway, and it supports
specific AWS directives to define endpoints, and authorizers (security). As this information is dynamic
(mainly the endpoints), we do not want to add it to the otherwise static microservices definitions, but
add it to the final specification at some later stage.
Here it comes a new utility, openapi4aws that does exactly that: it requires one or more files to update and a definition of the authorizers and all possible endpoints, and overwrites those files to include the full AWS information. This way, it is possible to re-import the specification to a working API gateway without having to manually / procedurally define its integration with the backend implementation
It is available in maven central, and the source is available in Github with an open source MIT license.
8th Dec 2021Windows: Git pull error on ssh-rsa
 Trying to update today my AWS CodeCommit repository in
my Windows virtual machine suddenly stopped, with the following error:
Trying to update today my AWS CodeCommit repository in
my Windows virtual machine suddenly stopped, with the following error:
Unable to negotiate with 52.94.48.161 port 22: no matching host key type found. Their offer: ssh-rsa fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists.
The access is done via ssh, so I thought there was an error on my .ssh/config file, or perhaps I had updated my ssh key in AWS and forgotten to download it to this box. After many checks, everything was fine, yet I couldn't git pull.
Stack overflow had the solution, it was needed to change the .ssh/config entry to look like:
Host git-codecommit.*.amazonaws.com IdentityFile ~/.ssh/aws User .... HostKeyAlgorithms +ssh-rsa PubkeyAcceptedKeyTypes +ssh-rsa
(Adding the last two lines)
7th October 2021sudo docker cp
 Last time (I hope) that the command
Last time (I hope) that the command
sudo docker cp
bites me. To access docker I need sudo access, and the files are copied in the target folder, owned by root. Not only I cannot likely access them, but if any folder within does not have a+w permissions, I cannot remove them either, as my sudo access is only limited.
Thanks to this stackoverflow link, I can use now instead the following python script to just copy from container source to host target:
from subprocess import Popen, PIPE, CalledProcessError
import sys
import tarfile
def main(source, target_folder):
export_args = ['sudo', 'docker', 'cp', source, '-']
exporter = Popen(export_args, stdout=PIPE)
tar_file = tarfile.open(fileobj=exporter.stdout, mode='r|')
tar_file.extractall(target_folder, members=exclude_root(tar_file))
exporter.wait()
if exporter.returncode:
raise CalledProcessError(exporter.returncode, export_args)
def exclude_root(tarinfos):
for tarinfo in tarinfos:
print(tarinfo.name)
if tarinfo.name != '.':
tarinfo.mode |= 0o600
yield tarinfo
main(sys.argv[1], sys.argv[2])
6th October 2021Virtualbox on Macbook Pro
A client requires that I access my remote
Windows machine through Citrix. At home I only have Linux or Mac computers, and whenever I login into Citrix,
and from there launch the remote desktop, the keyboard mapping is just broken. Entering simple characters like
a semicolon is a matter of trying the key several times: it will display a different character, until
eventually the semicolon appears. You develop quite an artistic to use copy and paste...
However, if I use a Windows virtual machine in Linux, the mapping works. Mind you, it implies that I am using a virtual machine to access some cloud bridge that links me to my remote desktop. Beautiful.
But using a Windows virtual machine in the Macbook, using virtualbox, shows abysmal performance. Plus, the screen will appear very tiny, requiring upscaling it (Virtualbox settings, Display, Scale factor). The best solution I have found to overcome this is executing Virtualbox in low resolution:
- Open Finder, then go to Applications and select VirtualBox
- Right clicks VirtualBox and select Show Package Contents
- Select now VirtualBoxVM Under Contents/Resources
- Right click VirtualBoxVM and select Get Info
- Check the checkbox Open in Low Resolution
Unfortunately, it affects all the virtual machines, and the display looks definitely worse, but the performance becomes really acceptable. I get that using Parallels or Vmware fusion would be a more performant solution, at a price (plus I could not transfer my Windows license).
A detail that still killed me was I needed Windows just to launch the remote desktop in Citrix. But inside Citrix, ALT+TAB would just show me the processes in Windows, not those in Citrix. Likewise, all hotkeys would be captured by the Windows virtual machine, rendering them mostly useless. Citrix to the rescue: open regedit in the Windows virtual machine and set the value Remote for name TransparentKeyPassthrough in the following two keys:
- HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Citrix\ICA Client\Engine\Lockdown Profiles\All Regions\Lockdown\Virtual Channels\Keyboard
- HKEY_CURRENT_USER\SOFTWARE\Citrix\ICAClient\Engine\Lockdown Profiles\All Regions\Lockdown\Virtual Channels\Keyboard\
19th Sep 2021Cancelling tasks
![]() When I developed
my first Intellij Idea plugin here, I did the usual customary checks,
and, pressed to share it with my team, I uploaded it to the Idea market place
When I developed
my first Intellij Idea plugin here, I did the usual customary checks,
and, pressed to share it with my team, I uploaded it to the Idea market place
The logic of the plugin is quite simple: read a file, obtain a token by invoking the aws binary with specified parameters, and then updating the initial file. These tasks are executed normally very quickly, but the modal dialog that shows the progress included a Cancel button, which I failed to handle. My initial thought was that the Idea runtime would just cancel the progress and stop my background thread. Which is definitely wrong: Java had initially a thread.stop method which was quickly deprecated. Although it can be used, it should not be used, and the Idea runtime definitely would be quite poor if it used it.
So Intellij Idea does the obvious: sets a flag if cancel is pressed, and it is the thread's task to check it regularly. Definitely a better solution, although the resulting code is uglier, invoking at almost every step a isCancelled() method.
And once I had to invest some time to have this running, I decided to decorate the plugin: in my rush, the initial version was just a bunch of labels + input fields. The presence of an image make it somehow better (or so I believe):
4th July 2021Backing up Thunderbird
 Each time aI setup a new
computer, I manage to have it up an running with my preferred configuration by following very well
defined steps, and taking advantage that most of my development
is based on git and I just need to clone my personal repositories.
Each time aI setup a new
computer, I manage to have it up an running with my preferred configuration by following very well
defined steps, and taking advantage that most of my development
is based on git and I just need to clone my personal repositories.
I have added now as well the instructions to replicate a Thunderbird profile, so the same accounts exist directly on the new setup.
26th June 2021Corsair 280X Build
 Last time I built my own computer
was in 2012. That was a quad core i3770 with 32 Gb that has served me well since then.
I do very little gaming (just Civ V) and most processing is handled in some remote machine,
so I haven't seen the need to upgrade to a newer machine.
But some operations start indeed to seem quite slow, and the PC can be noisy enough to be noticed as
soon as something requires some CPU power. Adding to this some problems with the video output,
I decided to get a new build.
Last time I built my own computer
was in 2012. That was a quad core i3770 with 32 Gb that has served me well since then.
I do very little gaming (just Civ V) and most processing is handled in some remote machine,
so I haven't seen the need to upgrade to a newer machine.
But some operations start indeed to seem quite slow, and the PC can be noisy enough to be noticed as
soon as something requires some CPU power. Adding to this some problems with the video output,
I decided to get a new build.
Nothing fancy: a Ryzen 5600x, and favouring small cases, I went for a matx mobo, the Asrock B550M Pro4 on a Corsair 280X box. Back in 2012, LianLi was the case to have, all brushed aluminium, high quality. This time, I was rooting for the LianLi PC-011D mini, but I had already purchased the Corsair case for a friend' build that finally hadn't happened, so I decided to use it for my build.
My previous build used a LianLi PC-V351 case, a small evolution of the PC-V350 that I had already used previously. These are nice cases, but not nice cases to tinker with. Opening it requires definitely a screw driver -6 screws to open any of the side panels-. Reaching the hard drives case could be done without screwdrivers, but fighting the connection of a small fan sitting behind. Any PCI card modification required opening the case totally, taking the motherboard out -all wires out-, and re-building it. Nice case, but nightmarish.
The Corsair 280X is 40% bigger: just a bit wider, less deep, and full 10cm higher: it looks bigger, but just slightly, until you start building the PC and realize how much space you have. And how well is all organized, and how well built is the case. It includes two fans that are totally silent.
I had purchased a Noctua cooler to replace the Wraith Stealth cooler that comes with the Ryzen 5600X, and thought initially on returning it: the default cooler has a distinct noise, but I thought that once closed the case, with its fans, you would not hear it. Then I mounted the Noctua NH-L12S, and I could not really know when the system was on or off, even when the case was still open! Kudos as well to the power supply, the also silent be quiet! Pure Power 11.
The only thing that bummers me about the build is a detail on the motherboard: the second M2 slot does not have all the lanes it should, so any PCI3 SSD you place there will run at lower speeds. I bought a cheap NVMe - PCIe adapter for 14 euros, and my measures are:
| Average read | Average write | Access time | |
|---|---|---|---|
| PCIe4 M2.1 slot | 3.5 Gb/s | 615.3 Mb/s | 0.02 ms |
| PCIe3 M2.2 slot | 1.6 Gb/s | 615.3 Mb/s | 0.02 ms |
| PCIe adapter | 2.9 Gb/s | 605.8 Mb/s | 0.02 ms |
So, same access time and average write, but definitely better using the additional adapter than the M2.2 slot. Which is therefore useless.
The only doubt I have now is that the case is beautiful, easy to serve, but mostly empty. How better a mini-itx build could have been...
9th May 2021CodeArtifact + Maven Idea plugin
![]() In a new project, we
needed to publish artifacts to a repository in AWS, using CodeArtifact. Instructions to do so are very
clear, but they are a poor
fit when using an integrated environment as Intellij Idea.
In a new project, we
needed to publish artifacts to a repository in AWS, using CodeArtifact. Instructions to do so are very
clear, but they are a poor
fit when using an integrated environment as Intellij Idea.
Basically, you would need to update an environment variable with an authorization token obtained by invoking a aws cli command. After setting the environment, you would need to launch the IDE -from inside that environment-. And aChs the token needs to be refreshed, it is needed to quit the IDE and repeat the process every 12 hours.
The solution was easy: instead of referring in the maven settings file to an environment variable, include there directly the received AWS token. And, to automate the process, better than using an independent script, why not having a Intellij Idea plugin that implements exactly this?
This plugin is defined here, already published in the public Idea plugins repository, and available in Github
6th March 2021TableFilter v5.5.3
 New release for this
Java library, with a small patch covering a rare null pointer
exception.
New release for this
Java library, with a small patch covering a rare null pointer
exception.
The source code and the issues management is now hosted in Github, and of course, the code has moved from Mercurial to Git. It is a funny coincidence: I started using SVN for the version control, and moved to Mercurial the 5th May 2010, using Google Code to host the repository. Exactly five years later, the 5th May 2015, I had to move from Google Code to Bitbucket, and almost exactly other 5 years later, the 7th May 2020, I have completed the migration from Bitbucket to Github. Which means ten years and two days of good Mercurial support. Shame that Bitbucket is kicking it out...
20th February 2021Recovering Touch Id on Macbook pro
In Summer 2019, my daughter gave me a badly
closed bottle of Fanta, with I placed in my laptop bag, together with my Macbook Pro. A short while later,
I learnt two things: that my bag was quite watertight and that the macbook was a well built machine that
had survived unscathed the Fanta puddle experience.
This happened during a flight to some holidays, where I used little or less the laptop, but eventually I realized that my fingerprint was not recognized anymore. Somehow I linked both experiences together, assuming that the liquid has affected / broken the T1 chip that handles the Touch Id. However, this seems a faulty theory, as T1 is used for other things -like driving the Touch bar' screen, which still worked fine.
I tried the possible options to get it working again. I could not remove existing fingerprints, resetting the NVRAM helped nothing, and a problem reported by other users -removing Symantec Endpoint protection- was definitely not my problem.
The only unproven solution was reinstalling MacOs. I had bought my laptop with Sierra installed, I had dismissed High Sierra and installed Mojave at some point, but didn't see any benefit on installing Catalina. Now, I was 30 months late, and Big Sur was calling, so I decided to go the hard way and install it from scratch, as a last try to get Touch Id working again.
And it did it. I am happy to have Touch Id working again, but dismayed to know that it can fail again -Fanta likely notwithstanding, and there is no obvious way to get it working again, except for a full re-installation.